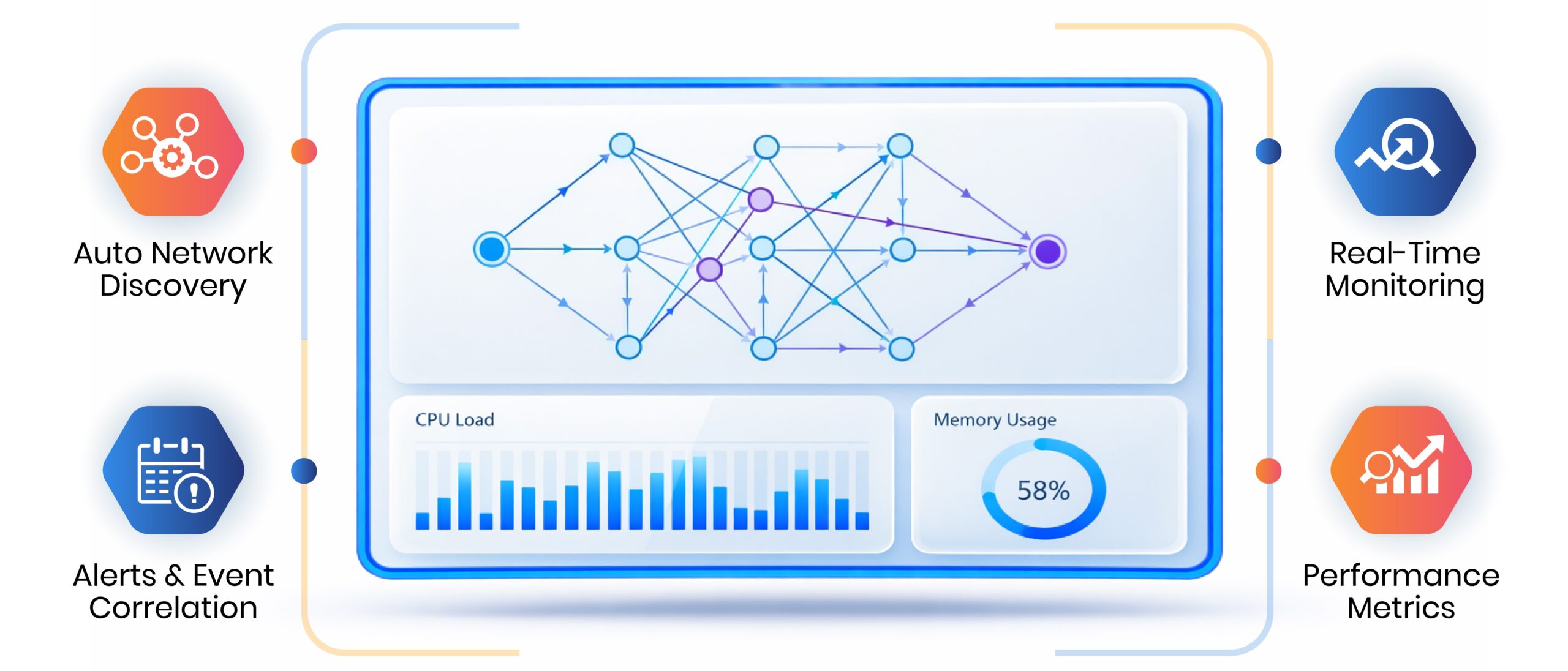
The ezAtlas NMS module cuts through the noise of complex enterprise networks by using smart auto-discovery to build a live, multi-dimensional view of your traffic. We turn raw infrastructure telemetry into actual intelligence, helping your team bridge visibility gaps and keep the entire distributed environment healthy. From aging on-premise hardware to fluid cloud instances, NMS makes sure your digital backbone stays resilient and fully tuned to your business needs.
Network Management
Features
Auto Network Discovery (SNMP, Agent-based, Agentless)
Manual tracking risks disappear through an automated engine utilizing SNMP polling, lightweight agents, and agentless protocols. This multi-layered logic identifies every device from core switches to remote endpoints for immediate console integration. Maintaining a live inventory prevents shadow IT and unauthorized hardware from entering the network environment undetected.
Device & Topology Mapping
Network architecture becomes visible through dynamic topology maps that update automatically as the environment evolves. Visualizing the physical and logical links between nodes reveals the infrastructure hierarchy to help pinpoint hidden bottlenecks. This technical oversight is vital for planning network expansion and maintaining a high-fidelity digital twin of the global enterprise estate.
Real-Time Health & Availability Monitoring
High-frequency uptime tracking monitors infrastructure via localized polling intervals. Automated logic checks network status 24/7 to maintain servers and cloud services within defined performance parameters. These live status updates identify degradation early, preventing minor fluctuations from becoming total outages.
Threshold-Based Alerts & Notifications
Alerts trigger upon metric deviation from a defined baseline. Latency spikes or bandwidth drops prompt the platform to push data through Email, SMS, or Webhooks. This transmission facilitates intervention before performance issues hit end-users or the wider business environment.
Event & Alarm Correlation
A correlation engine groups related network events into single alarms to cut through operational noise. Identifying causal links between multiple warnings allows administrators to bypass symptoms and target the root cause. This logic accelerates troubleshooting and ensures priority goes to high-impact resolutions.
Utilization tracking across physical and virtual assets indexes health across the infrastructure. KPI monitoring aligns hardware allocation with peak load demands. Historical trend data flags specific upgrade windows, removing the reliance on emergency procurement.
Centralized Monitoring Dashboard
NOC operations consolidate within a single interface built for executive oversight and technical drill-downs. Real-time health scores track global infrastructure across multi-site and hybrid cloud environments. Customizable layouts center mission-critical data within the primary operational view.
Dependency Mapping for Impact Analysis
Mapping links between infrastructure and business services reveals the ripple effect of network events. This logic facilitates impact assessments during maintenance or outages, keeping priority on mission-critical processes. Identifying which departments rely on specific hardware allows for precise stakeholder management.